這次在 Modern Web 分享的 pppr 就是之前在處理 SSR 所開發的一個後端套件,可以讓前端工程師不用改任何一行程式碼,純粹在後端就可以把這個難搞的問題完美解決。
內容包括 CSR 及 SSR 的比較,以及 pppr 在開發時所遇到的問題,以及如何解決這些問題。如果前端在處理 SSR 時遇到不少問題,可以來試試 pppr,一定會讓你節省不少時間!
現在大家使用 Funliday 在「景點瀏覽」輸入城市,或者是移動地圖出現的推薦景點,應該都是即時出現,也是最近花了一些時間的成果。下面先筆記一下推薦景點開發的歷程,之後如果有機會應該可以到 PostgreSQL.TW 分享一下完整的內容。
簡單來說,就是一個從 70000ms 的 response time,提升到 200ms 的 response time 過程。
如何用 PostgreSQL 的 advisory lock 實作推薦景點
上星期大家都有來聽小編在 COSCUP 分享的「模糊也是一種美 - 從 BlurHash 探討前後端上傳圖片架構」嗎?這個技術已經有實作在 Funliday 的 Web 跟 Android 囉。這個議題結束後,有朋友問了一些問題,這裡順便來統整回答一下。
signed URL 是為了讓沒有 access key 及 secret key 的 sender 也能在有權限管理的保護下做 S3 的檔案處理,而 Funliday 在這裡的實作是不用原檔名做 key,改用 UUID 產生避免檔名衝突。
在做 BlurHash decode 的時候因為用到的是 CPU 運算,而且 JavaScript 又是 single thread 的關係,所以在 decode 同時移動畫面的話,可能會造成 CPU 不夠力的 client 會有極短暫的延遲時間。這時候可以考慮把 decode 丟到 web worker 處理,避免卡到 UI thread 的順暢度。用 Android 的術語來說就是開 AsyncTask 啦!
原先是使用 server side (2) 的方式,但在處理 MQ 上傳後的 notify 花了不少時間,而且上傳到 S3 也沒這麼快,所以後來改用 client side 的方式做上傳功能,運作上也比原先的方式順暢。
因為 medium 檔案比 BlurHash 的字串大很多,而且要多發一次 request,成本比 BlurHash 高出不少,所以我們認為用 BlurHash 會是比較好的。
當然也是要感謝 gslin 大大,他在 4/26 (日) 簡單介紹了 BlurHash。小編下午看到這篇文章,馬上丟去 slack 問我們的設計師大大,看她覺得這效果如何?她過沒多久回覺得不錯,小編就在星期日的下午開始處理 server side 的實作。隔天星期一有了初步的成果,然後給我們的安卓五星上將看,星期二就完成 Android 實作並上線了!
也是因為 CDN 那塊後來把原先的 lambda 改用自己寫的 server 處理,所以實作 BlurHash 才能這麼快。lambda 這塊也是血淚史,下略 10000 字,之後有機會再跟大家分享。歡迎大家對這塊有興趣的也來交流一下喔!
這一系列文總共有三篇,這是最後一篇。
Funliday 重磅推出新的 prerender 套件 pppr!這是一個 zero config 的 express middleware,只要 npm install pppr,然後在 app.js 裡面加一行 app.use(pppr()) 就可以直接拿來用了。
原本在使用 prerender.io 這個套件有時候會出現 504 timeout 的問題,後來發現這個套件用的是比較底層的 API (Chrome DevTools Protocol, CDP),研究它的原始碼後發現 render HTML 的 timeout 判斷上有些怪怪的,本來想試著去改這塊,但對 CDP 不熟,所以用 puppeteer 重寫一套 prerender service,pppr 也就應運而生。
簡單先解釋一下,puppeteer 是基於 CDP 封裝後成為比較容易使用的 API。因為 client side rendering (CSR) 的流行,所以現在要做網路爬蟲的話,愈來愈多會選擇用 puppeteer 來處理。這裡來分享一下在開發 pppr 的時候,有哪些東西要注意的。
因為每個使用者接收到這個訊息之後,因為要顯示 og data,所以就會去打一次 prerender。這裡姑且先稱之為 OG-DDoS 好了 XD,所以一定要做 cache,讓第一個 request 把 HTML 產生出來之後就放到 cache 裡面。然後可以用 LRU cache 來處理,因為這類 URL 都是短時間會被大量使用,之後就很少被用了,用 LRU cache 剛剛好。
如果在第一個 request 還沒產生出 HTML 之前,第二個同樣 request 就進來了,這樣子 cache 可以說是根本沒作用,還要再找時間來處理 lock 機制才行。
如果沒有每個 request 都開新 page 的話,會造成 A request 還沒處理完,B request 就用同一個 page 做 render,這樣子 A request 就會 504 timeout 了。所以一定要記得每個 request 都要新開 page。
因為 headless chrome 的 user agent 就叫做 HeadlessChrome,為了避免在 render 的時候會出現意料外的狀況,保險一點還是把 HeadlessChrome 改成 Chrome 會比較好。
因為 expressjs 跟 puppeter 是兩個不同的 context,對於 redirection 來說,expressjs 會回傳 3xx 系列的狀態碼,但 puppeteer 則會直接執行完成。所以把 puppeteer 放在 expressjs 裡面執行的話,必須要處理 redirect chain,讓 expressjs 能回給 client 正確的狀態碼才行。
pppr 因為是發想自 prerender.io,所以 interface 也一樣是 /render?url=https://example.com。但有時候原始的 url 後面會包含 query string,所以 expressjs 要用 URLSearchParams 另外做些處理,才能取得完整的 url。
開發 pppr 基本要注意的事項大概就這樣,總之記得給星,有任何問題歡迎發 issue 跟 pr 喔!
這一系列文總共有三篇,這是第二篇。
上一篇解決了 social network 抓取 head tag 裡面的 title, og data 等問題,但其實還有 search engine 要解決,因為 social network 只看 head,但 search engine 除了 head 以外也會看 body,所以這篇要來解決 body 一模一樣的問題。
傳統的 web 開發方式通常是一條龍開發 (你就是那條龍!),後端取得資料庫的內容,然後組成 HTML 之後丟到瀏覽器上顯示。現代的 web 開發方式通常就是一個前端配一個後端,後端專注於把資料送給前端,前端專注於取得資料後在瀏覽器上面顯示漂漂亮亮的。而傳統方式稱為 server side rendering (SSR),現代方式就稱為 client side rendering (CSR)。兩者開發方式各有優缺,蠻多文章有提過,這裡也就不另外說明了。
比較簡單判斷 CSR/SSR 的方式可以直接在你想知道的網頁,按下 Ctrl+u (Windows, Linux) 打開原始碼,看看實際上顯示的內容跟原始碼是不是差異過大。如果網頁內容很豐富,但原始碼才十幾二十行而已,那可以很粗略的說這是 CSR,如果基本上一致那就可以說是 SSR。
而 search engine 就是靠著原始碼把網頁內容做索引,所以如果谷歌大神到 CSR 的網站爬網頁內容,最後爬到的 body 當然都是同一份內容,這樣子對於 SEO 上是不合格的,所以這裡就要分享一下 Funliday-旅遊規劃 是如何處理這塊的。
第一種方式,可以用 VAR 這三套前端框架各自支援的 SSR 方案來處理,像是 Nuxt.js, Next.js, Angular Universal,這些內容已經有許多前輩分享,這裡就不另外說明了。但要注意一點,就是導入這類的解決方案通常會影響到原本的開發模式,像是 webpack 跟 bootstrapping 的方式就一定會動到,小編是建議對框架真的很熟悉之後,再來用這方式會比較好。
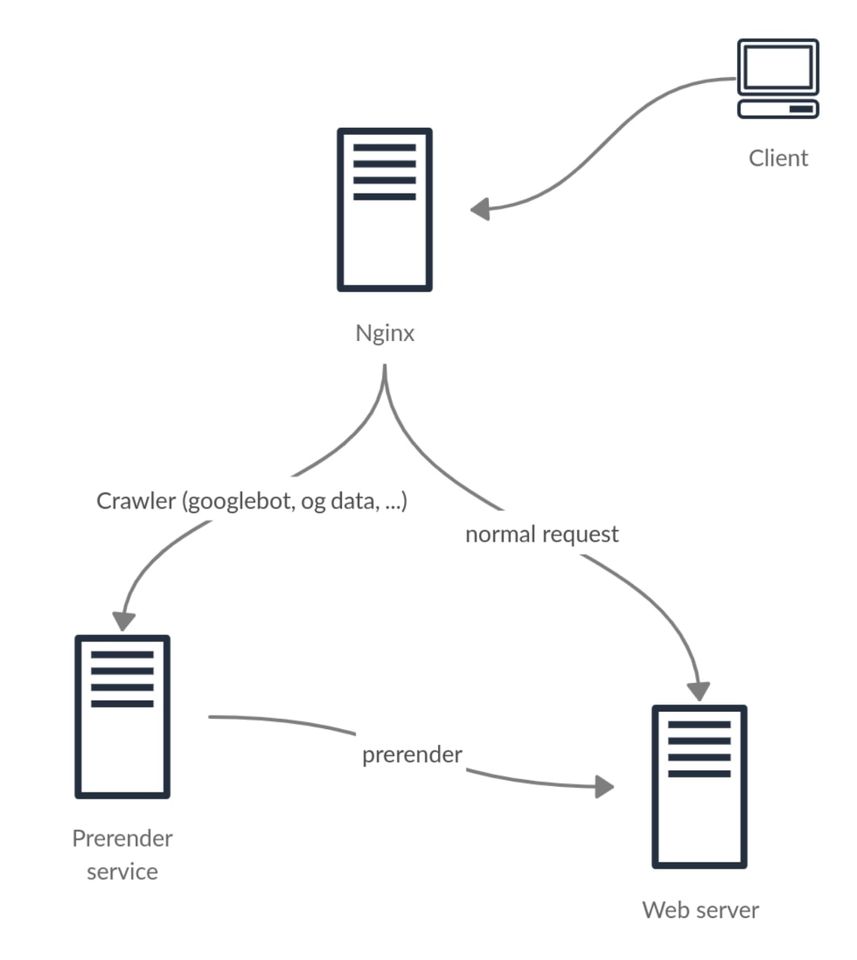
第二種方式,就是這次的重頭戲 prerender 了。prerender 也不是什麼魔法,就是一句話「讓爬蟲看到它應該要看的內容」。如圖所示,當 Nginx 收到 request 之後,發現 user agent 是 googlebot 就轉送到 prerender service,如果是一般 request 就直接丟到後面原本的 web server。
而 prerender service 接到 request 之後,就執行 headless chrome (用程式控制沒介面的 Google Chrome),把原本的網頁用 CSR 處理完之後,再把 HTML 的完整資料傳回給 googlebot,這樣子就達到「讓爬蟲看到它應該要看的內容」的功能了。原本的程式完全不用改,只要在 Nginx 做處理就可以了,也是負擔相對較小的方式。
另外,用了 prerender 之後,原本第一篇為了 title, og data 所做的調整也可以拿掉了。因為 CSR 本來就可以改 title, og data,所以避免重複做一樣的事,app.get("*") 這個 route 裡面關於 metadata 的功能也可以直接刪掉了。
那為什麼還會有第三篇?因為 Funliday 實際在應用 prerender.io 似乎有些問題,所以我們就改成自己寫 prerender 了,原因下回說明。
這一系列文總共有三篇,這是第一篇。
對於用 Vue, Angular, React 這類前端框架來講,如果沒有對 search engine 或 social network 特別處理的話,出來的結果一定不會如你所想的一樣。
因為 client side rendering (CSR) 的作用域通常是在 body 裡面的 container,所以對於 search engine 或 social network 來說,container 外的 head tag 只是一層皮,裡面的資料基本上沒有什麼用,因為解析出來的內容都一模一樣,沒有獨特性。
1 | app.get("*", async (req, res) => { |
為了要讓每一頁的 head tag 都不一樣,最簡單的方式就是在 web 這一層的 expressjs server 多加一個特殊的 route,去 catch 所有 web 的 get request,類似上面的程式碼。
然後搭配 path-to-regexp 來設定特定 url pattern 做不同的 head tag 設計,比如 kewang/trips/123 的 title 叫做 “kewang 的台北二天一夜行程”,kewang/journals/456 的 title 叫做 “kewang 的宜蘭三日遊記”,當然這裡的例子舉的很簡單,正規的做法應該要搭配資料庫來取得對應的 title 跟 og data 才對,也就是附圖程式裡面的 loadMetaDataFunction。
只要做好這類的處理,在 social network 上面應該就可以所向無敵了。但這世界可不只有 social network,更恐怖的谷歌大神還在後面等著你咧!
下一篇就來講一下如何對付搜尋引擎吧。
Funliday 身處武漢肺炎疫情最慘重的觀光業中心,雖然大家都不出去旅遊,但我們也趁著這個時間增強自己的核心功能,小編今天來聊一下其中一個功能的技術議題。
Funliday 有個功能是把外部文章直接顯示在 Funliday 的 App 跟 Web 上,但遇到了一些技術性及著作權的問題,相信應該也有朋友遇到過類似的狀況,今天就來分享一下吧。
在 Funliday App 上的顯示還算好處理,直接用 WebView 呈現就好,但在 Funliday Web 上就很難處理,這邊整理一下技術上可以實作的幾種方式。
最暴力的方式,直接用 iframe 嵌入對方網址,但會有一些問題。像是無法讓 Google 大神爬內容、HTTP 網址無法嵌入、如果有設定 x-frame-options 為 SAMEORIGIN 的話就無法嵌入、CSP 的設定也有可能造成無法嵌入
改善了第 1 種方式,直接在 Funliday server 這裡做 proxy,但還是會有無法讓 Google 大神爬內容以及內容網址如果是相對路徑時的導頁問題 (這應該好解決)
比如 A 站就固定抓 <div class="content">,B 站就固定抓 <article> 的內容,然後直接顯示在 Funliday Web 上,但畫面可能會亂掉,所以要想辦法把 A 站跟 B 站的 CSS 也拿來用,在 CSS 前面也要想辦法加上 namespace 避免衝突
類似 2+3 的方式,就是把要顯示的網頁用 headless chrome render 完之後,再跟原本的內容一起顯示,但畫面應該是會亂掉。
技術面可以的解法都確認了之後,再來就是適法性的問題了,因為 234 會把對方的資料落地到 Funliday 上,所以可能會有著作權的問題。對科技及法律這塊當然要問有研究的 ant 啦,請教了 ant 之後也得到了一些結論。
234 都會有著作權法的問題,所以基本上是不可行的,但只要著作權人有同意的話,則不在此限。
最後 Funliday Web 的實作方式跟 1234 都無關,而是改用類似預覽頁的方式在 Funliday Web 顯示原連結的 og:title 及 og:image,應該會再加上簡單如「以上內容未經重製與改作,來源均援引來源網頁內容」的聲明。
對於技術這部分也不複雜,在後台上稿時先取得原網頁的 og 資料,跟原本的 234 相比簡單太多了 XD
有經過 ant 同意,認為這個問題應該蠻多人都會遇到,所以分享給大家看看啦!
小編好久沒發文了 Orz,來發個近日資訊業最大條新聞跟個人看法
GitHub 被微軟買走之後做了蠻多事情,像是前幾個月 npm 被 GitHub 買下來,但這其實也不意外,因為這兩年 GitHub 在 JavaScript 的支援度就愈來愈高,不止可以在網頁上面做 audit,也可以做 navigate,功能蠻齊全的。被買下來之後,之後可以期待在 GitHub 上面直接 deploy npm 模組了。
另外一個就是這次的 private repo 完全免費了,小編記得之前 private repo 免費好像有些限制,像是只限 5 人的樣子,但現在可說是完全不限,有富爸爸果然是不一樣!
再來說一下個人選擇,如果是可以給一般人看的內容,小編一定是用 GitHub,畢竟資訊人誰沒有一個 GitHub 帳號呢?然後個人接案因為不能公開原始碼,所以當然放在 GitLab (以前是 Bitbucket)。現在 Funliday 的 git repo 因為原始碼不能公開,當然也是放在 GitLab。
然後因為 Funliday server 是放在 Heroku 上面,Heroku 上面有個功能可以直接結合 GitHub 的 push 之後 deploy,但因為 Funliday 用的是 GitLab,所以沒辦法直接用這功能,只能繞個彎改用 dpl,把 GitLab 整合進 Heroku 裡。
但也因為用了 GitLab 之後,才知道它的功能比 GitHub 多太多,對一般公司所需要的權限控制,小編是覺得比 GitHub 完整。然後對於 CI/CD 的支援度也很強大,現在還支援 build docker image 的功能。
不過當 GitHub private 免費之後,對於沒有依賴 GitLab 權限控制或 container 功能的使用者,還蠻有可能移回 GitHub 的,畢竟能在同一個 hosting 操作當然比較方便。所以以後小編開 repo 的考量,可能就不再是 private 或 public 了,而是在於 deploy 的方便性,或是能不能 build 出 artifact 了。
這次在 Modern Web 的分享,主要是講開發 POI Bank 時要注意的一些內容,其中 OSM 跟 PostgreSQL 又是非常重要的一環。對開發景點資料庫有興趣的朋友,決定不能錯過!
其實 POI Bank 的內容遠遠不只這些,有許多功能還沒有提到,像是 autocomplete 及搜尋,尤其搜尋又是重中之重,一直沒能好好處理。因為大家被 Google 訓練的實在太好了,POI Bank 的下一步就是要把搜尋精準度做好。這就要靠大家多多使用 Funliday,就有更多的資料可以訓練了 XDDD
Ant 分享的內容總是很有意思,這場學到許多東西。連 Netflix 這麼大的公司都這樣講了,要在 production 做測試!
小編最近在 Funliday 切環境的時候非常有感。新創錢不夠多,總不可能建置一模一樣的環境來做測試吧。像是現在為了省錢,所以 Elasticsearch、Redis 和 Worker 還是有部分只在 production 上運作。這樣子在做測試時還是有部分怕怕的,尤其是目前主機大都在 Heroku 上面,也還是有部分的 env 需要做調整。
無論如何,還是要有錢才能把環境完全切開才行啊 Orz