這一系列文總共有三篇,這是第二篇。
上一篇解決了 social network 抓取 head tag 裡面的 title, og data 等問題,但其實還有 search engine 要解決,因為 social network 只看 head,但 search engine 除了 head 以外也會看 body,所以這篇要來解決 body 一模一樣的問題。
傳統的 web 開發方式通常是一條龍開發 (你就是那條龍!),後端取得資料庫的內容,然後組成 HTML 之後丟到瀏覽器上顯示。現代的 web 開發方式通常就是一個前端配一個後端,後端專注於把資料送給前端,前端專注於取得資料後在瀏覽器上面顯示漂漂亮亮的。而傳統方式稱為 server side rendering (SSR),現代方式就稱為 client side rendering (CSR)。兩者開發方式各有優缺,蠻多文章有提過,這裡也就不另外說明了。
比較簡單判斷 CSR/SSR 的方式可以直接在你想知道的網頁,按下 Ctrl+u (Windows, Linux) 打開原始碼,看看實際上顯示的內容跟原始碼是不是差異過大。如果網頁內容很豐富,但原始碼才十幾二十行而已,那可以很粗略的說這是 CSR,如果基本上一致那就可以說是 SSR。
而 search engine 就是靠著原始碼把網頁內容做索引,所以如果谷歌大神到 CSR 的網站爬網頁內容,最後爬到的 body 當然都是同一份內容,這樣子對於 SEO 上是不合格的,所以這裡就要分享一下 Funliday-旅遊規劃 是如何處理這塊的。
第一種方式,可以用 VAR 這三套前端框架各自支援的 SSR 方案來處理,像是 Nuxt.js, Next.js, Angular Universal,這些內容已經有許多前輩分享,這裡就不另外說明了。但要注意一點,就是導入這類的解決方案通常會影響到原本的開發模式,像是 webpack 跟 bootstrapping 的方式就一定會動到,小編是建議對框架真的很熟悉之後,再來用這方式會比較好。
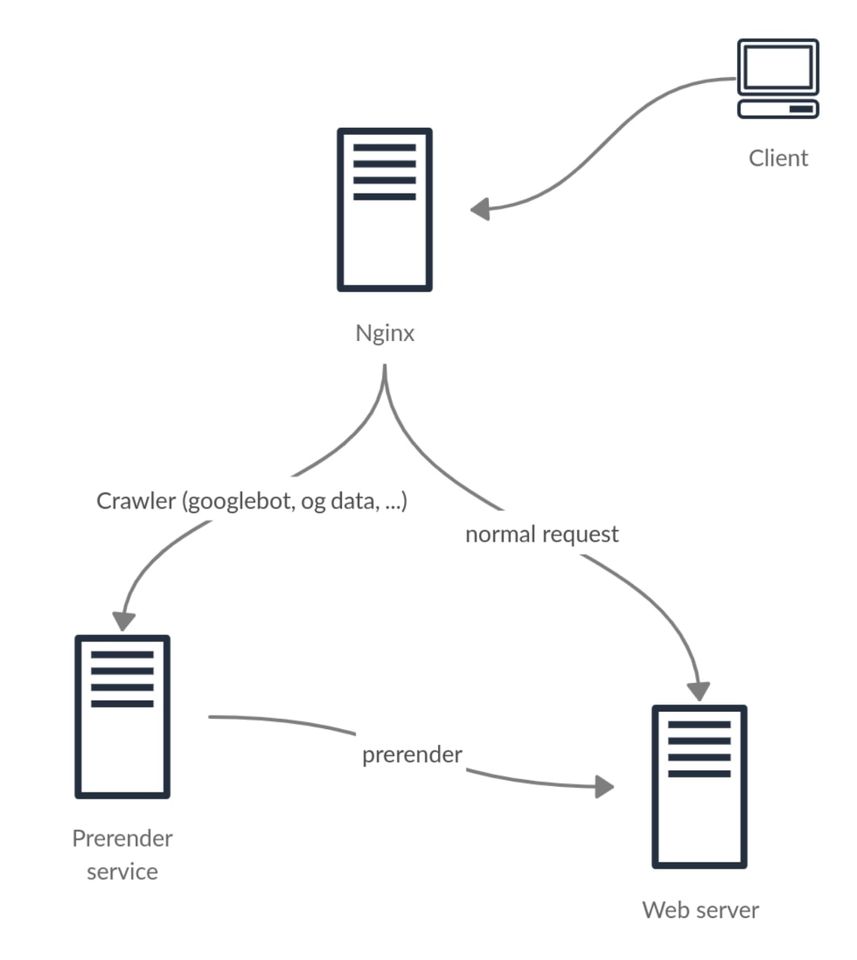
第二種方式,就是這次的重頭戲 prerender 了。prerender 也不是什麼魔法,就是一句話「讓爬蟲看到它應該要看的內容」。如圖所示,當 Nginx 收到 request 之後,發現 user agent 是 googlebot 就轉送到 prerender service,如果是一般 request 就直接丟到後面原本的 web server。
而 prerender service 接到 request 之後,就執行 headless chrome (用程式控制沒介面的 Google Chrome),把原本的網頁用 CSR 處理完之後,再把 HTML 的完整資料傳回給 googlebot,這樣子就達到「讓爬蟲看到它應該要看的內容」的功能了。原本的程式完全不用改,只要在 Nginx 做處理就可以了,也是負擔相對較小的方式。
另外,用了 prerender 之後,原本第一篇為了 title, og data 所做的調整也可以拿掉了。因為 CSR 本來就可以改 title, og data,所以避免重複做一樣的事,app.get("*") 這個 route 裡面關於 metadata 的功能也可以直接刪掉了。
那為什麼還會有第三篇?因為 Funliday 實際在應用 prerender.io 似乎有些問題,所以我們就改成自己寫 prerender 了,原因下回說明。
- Prerender.io: https://prerender.io