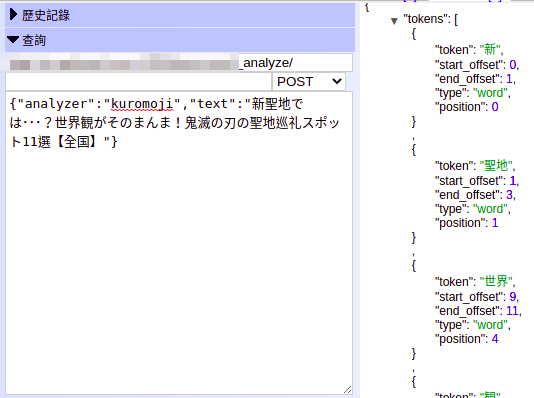
直接舉例,很少人會打「我要去板橋區逛夜市」,應該都是打「我要去板橋逛夜市」吧?在 Funliday 裡面,資料庫存的都是官方名稱「板橋區」、「花蓮縣」,但使用者一般不會直接打全名,能讓使用者少輸入就儘量少輸入,所以有了 alias 這個機制的產生。
1 2 3 4
板 板橋 板橋山*123457 板橋區*123456
照原本的邏輯來看,如果輸入「板橋」的時候,candidate 會照順序顯示「板橋山」、「板橋區」,這也是之前提到的 Sorted Set。但加了 alias 的邏輯之後,則會照順序顯示為「板橋」、「板橋山」,儲存方式會變下面這樣:
1 2 3 4 5
板 板橋 板橋*123456 板橋山*123457 板橋區*123456
使用者對於板橋到底是「市」還是「區」根本不在意,所以需要有個 alias 可以顯示出來,邏輯會變這樣:
graph TD;
A[開始] --> B[將內容使用 id 做分組];
B --> C{判斷單一組裡面的個數有幾個};
C -->|只有一個| D[直接加入 candidate list];
C -->|超過一個| E{判斷裡面有沒有 alias};
E -->|有| F[把 alias 加入 candidate list];
E -->|沒有| G[走原本的邏輯];
D --> END;
F --> END;
G --> END;
END[結束];
其實這也是一開始設計的時候沒處理好,這樣子真的不知道是「台北市的中山區」,還是「基隆市的中山區」,所以我們最近把 parent city 也加上去了,所以會變成這樣子顯示:
1 2
中山區, 基隆市, 台灣 中山區, 台北市, 台灣
其實我們的許多資料都是從 Open data 來的,但 parent city 這個就不一定全世界都有,所以我們由土法煉鋼的方式。原則上 candidate city 應該會被 parent city 的範圍包住,所以用 PostGIS 的 ST_Intersects 來計算全世界的 parent city,這個也跑了好幾天才跑完。
但因為 Open data 的 boundary box 不一定很準確,相對的 parent city 也是有一些錯誤。這段就真的只能透過工人智慧來解決問題了。
7. 移除連續重複名稱
這個主要是從新加坡的需求而來的,新加坡既是國家,也是城市。但顯示出來就會變成下面這樣:
1
新加坡, 新加坡
這樣子真的有點奇怪,所以我們想了一個方式,目前既然有了 city, parent, country 這三層的結構,所以如果有任兩個連續一樣名稱的話,就只留一個就好,調整後會變下面這樣子:
然後將 ES 裡面所有的景點全部再重跑一次 index (將資料儲存至 ES 裡面)。在重跑 index 前,Funliday 會用一些 NLP 的技術來判斷原本在 ES 裡面的景點是中文或日文。如果是日文的話,我們會再丟入中文詞庫裡面判斷詞性,如果是名詞的話,我們就會把這個景點名稱也認定為是中文。
graph TD;
A[開始] --> B{判斷景點名是中文或日文};
B -->|中文| C[儲存到中文欄位];
C --> END[結束];
B -->|日文| D[儲存到日文欄位];
D --> E{丟入中文詞庫判斷詞性};
E -->|名詞| F[可能是中文];
F --> C[儲存到中文欄位];
E -->|非名詞| END[結束];
最近 Funliday 常發一些精選旅遊回憶的 App 通知給使用者,在去年十一二月的時候發通知 Server 還能撐的了瞬時大流量的 request。
但今年開始發這類通知,總共發了三次,三次都造成 Server 被打掛,而且重開 AP 還緩解不了,瞬間手足無措。大概都要等過了十分鐘左右,Server 才將這些 request 消化完。
這裡就來簡單整理一下時間軸,順便分享一下 Funliday 是如何解決這個問題。
1/6 1900:系統排程發送精選旅遊回憶的 App 通知
1/6 1900+10s 開始:Server 收到極大量的 request
1/6 1900+20s:Nginx 出現錯誤訊息 1024 worker not enough,並回傳 http status code 503
1/6 1900+25s:PostgreSQL 出現錯誤訊息 could not fork new process for connection (cannot allocate memory)
1/6 1900+38s:Node.js 收到 PostgreSQL 的 exception。There was an error establishing an SSL connection error
1/6 1900+69s:PostgreSQL 出現錯誤訊息 database system is shut down
1/6 1900+546s:PostgreSQL 出現錯誤訊息 the database system is starting up
看了時間軸就覺得奇怪,先不論 10s 的時候發了極大量 request,造成 20s 在 Nginx 出現 worker not enough 的錯誤訊息。而是要關注 25s 時的 PostgreSQL 出現 could not fork new process for connection 的錯誤訊息。
這邊來分享一下自己程式碼的寫法,上面是原始寫法,在每個 API 都 create 一個 db client instance 來處理該 API 層的所有 db request。這是蠻單純的做法,也是 day 1 開始的處理方式。但有個小問題,就是每個 API 層都要自己 create instance,不好管理,且浪費資源。